
In today’s digital era, the exponential growth of data generated through educational platforms has posed unprecedented challenges, particularly concerning the privacy of personally identifiable information (PII). As educational institutions and researchers increasingly rely on large datasets to enhance learning outcomes and innovate pedagogical techniques, the imperative to safeguard student privacy has never been more critical. This project addresses the intricate balance between leveraging educational data for research and ensuring the confidentiality of student information. By developing sophisticated machine learning models, our initiative aims to detect and anonymize PII effectively, thereby reducing risks and expanding the utility of educational datasets for research and development without compromising privacy.
Data Sources and Dataset Description
Overview of the Project Dataset
The core of our study revolves around a dataset composed of approximately 22,000 student essays collected from a massively open online course (MOOC). These essays were responses to a standardized prompt that required students to apply theoretical knowledge to practical problems, providing a rich source of natural language data. The data can be downloaded here.
Data Protection Measures
From the outset, maintaining the privacy of the students was paramount. To this end, all personally identifiable information originally present in the essays was anonymized using surrogate identifiers before analysis. This preemptive measure was essential to protect students’ identities while allowing us to perform meaningful data analysis and machine learning.
Dataset Composition and Access
Our dataset predominantly consists of test essays, which make up about 70% of the total data. This significant proportion underscores the importance of our project, as it highlights the need to enhance the data with additional, publicly available external datasets to improve the robustness of our training models. The dataset is formatted in JSON, facilitating ease of access and manipulation. Key elements include:
- Document Identifier: Each essay is uniquely identified, allowing for precise referencing and analysis.
- Full Text: Essays are presented in their entirety in UTF-8 format, ensuring that the data remains consistent and accessible across different systems.
- Tokens and Annotations: Utilizing the SpaCy English tokenizer, essays are broken down into tokens. Annotations follow the BIO (Beginning, Inner, Outer) format, which helps in identifying and classifying different types of PII. For example, tokens labeled as “B-NAME_STUDENT” signify the beginning of a student’s name, while “I-NAME_STUDENT” indicates a continuation.
Types of PII to Be Identified
For the purposes of this project, we focused on detecting seven specific types of PII within the essays, each representing a unique privacy concern:
- NAME_STUDENT: Names directly associated with individual students.
- EMAIL: Email addresses that could be used to contact or identify a student.
- USERNAME: Usernames that might be linked to student profiles on various platforms.
- ID_NUM: Identifiable numbers, such as student IDs or social security numbers.
- PHONE_NUM: Telephone numbers associated with students.
- URL_PERSONAL: Personal URLs that could directly or indirectly identify a student.
- STREET_ADDRESS: Residential addresses, either complete or partial, that are tied to students.
Detailed Preprocessing Steps: Enhancing Data Readiness for PII Detection
After initial data cleaning and normalization, our preprocessing approach involved several critical steps designed to refine the dataset further, making it ideal for effective machine learning analysis. This process ensures that the data not only meets the technical requirements of our models but also aligns with our objective to detect PII accurately.
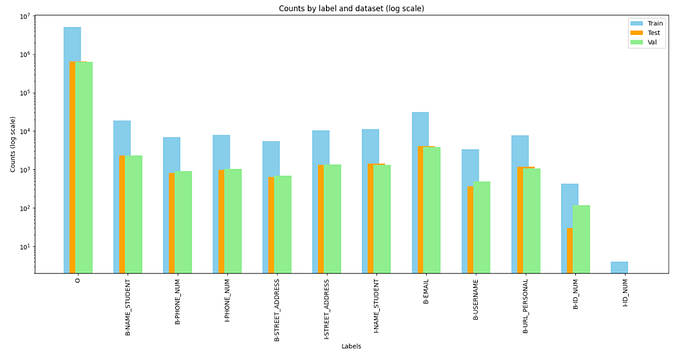
Calculating and Analyzing Label Frequencies
Understanding the distribution of labels within our dataset was crucial. By calculating the frequency of each label, as shown below, we gained insights into the prevalence of different types of PII, which helped in prioritizing certain types for more focused analysis and model training.
Label Mapping and Replacement
To facilitate easier processing and improve readability during model training, we mapped numerical labels to their corresponding string representations using a predefined dictionary. This step was essential for maintaining clarity and consistency across the dataset. For instance, numerical labels were converted as follows:
- 1: ‘B-NAME_STUDENT’,
- 2: ‘I-NAME_STUDENT’,
- etc.
After mapping, we replaced the numerical labels with these string labels throughout the dataset. We also recalculated frequencies post-replacement to confirm that no errors were introduced during this transformation.
Data Filtering and Token Validation
Select rows of the DataFrame were filtered based on specific label values, which allowed us to focus on more significant or underrepresented PII types. Additionally, we implemented a function to validate tokens, ensuring that only relevant and correctly formatted data was retained for model training. This step helped in eliminating any corrupt or outlier data that could skew the model’s learning.
Organizing Data at the Document Level
Our preprocessing also included grouping tokens and their corresponding labels by document. This organization was pivotal for maintaining the narrative and contextual integrity of each essay. Further, we iterated over tokens and labels for each document, which allowed detailed examination and ensured that the data adhered to our labeling schema accurately.
Preparing Data for Modeling
Finally, we concatenated tokens into sentences and converted label sequences into lists of strings. This preparation was crucial as it transformed the tokenized data into a format suitable for the sequential processing capabilities of our chosen NLP models. This step ensures that when fed into models like BERT and ELECTRA, the data is in an optimal state to be processed efficiently and effectively.
Exploring Different Models: XLNet, LSTM, and GRU in PII Detection
As part of our comprehensive approach to detecting personally identifiable information (PII) in educational datasets, we experimented with a variety of machine learning models, each offering unique strengths and challenges. While our primary focus was on the performance of BERT and ELECTRA, we also explored the capabilities of XLNet, LSTM, and GRU, with mixed results in the context of PII detection.
XLNet: Advanced Permutation-Based Modeling
XLNet extends the capabilities of the Transformer-XL model through Permutation Language Modeling. This innovative approach allows XLNet to capture bidirectional contexts by considering all possible permutations of the input tokens, which theoretically provides a more comprehensive understanding of the text’s context. Despite these advanced features, XLNet did not achieve the level of performance we observed with BERT and ELECTRA in our PII detection task. We believe this discrepancy may be due to XLNet’s complexity and its general training methodology, which might not align perfectly with the specific nuances and varieties of PII embedded within educational texts.
LSTM and GRU: The Challenges with Recurrent Networks
LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Units) are types of recurrent neural networks (RNNs) renowned for their effectiveness in sequence prediction tasks across various NLP applications. These models process data sequentially, which is beneficial for capturing temporal dependencies in text data.
However, in our project, both LSTM and GRU faced difficulties in managing the complex dependencies and contextual nuances required for effective PII identification. Their sequential nature, while powerful for many tasks, proved less effective than the Transformer-based models in handling the intricacies of detecting and classifying dispersed and nuanced PII data in large texts. The challenges were particularly pronounced when dealing with the scattered nature of PII in student essays, where context plays a crucial role in accurately identifying sensitive information.
Harnessing ELECTRA for Enhanced PII Detection: A Deep Dive into Architecture and Implementation
ELECTRA’s Innovative Language Modeling Approach
ELECTRA, an acronym for Efficiently Learning an Encoder that Classifies Token Replacements Accurately, marks a significant departure from traditional language model training approaches like Masked Language Modeling (MLM) used by BERT. ELECTRA introduces the Replaced Token Detection (RTD) technique, which innovatively utilizes every token in the input by substituting some tokens with plausible yet incorrect alternatives. This method allows the model to assess the authenticity of each token, enabling comprehensive learning from the entire input sequence, thereby maximizing data efficiency and training effectiveness.
Advantages of ELECTRA’s RTD Method
Unlike traditional MLM that only learns from approximately 15% of the data (the masked tokens), ELECTRA’s RTD approach evaluates every token in the input, thus learning more effectively from the full context. This leads to faster learning rates and reduces the computational resources required, allowing ELECTRA to achieve or even surpass benchmarks set by other advanced models like RoBERTa and XLNet with significantly less computational overhead.
ELECTRA’s Dual Model Architecture
ELECTRA operates with a unique dual model architecture consisting of two transformer models: a generator and a discriminator. This setup is somewhat analogous to generative adversarial networks (GANs), but tailored for language processing without the adversarial component. The generator model produces plausible token replacements, while the discriminator evaluates whether each token in the sequence is genuine or a replacement. This dynamic interplay enhances the model’s ability to understand and process complex language patterns, thereby improving its generalization capabilities across various NLP tasks.
Project Implementation and PII Detection with ELECTRA
In our project to detect personally identifiable information (PII) from voluminous datasets, ELECTRA’s robust NLP capabilities were instrumental. We embarked on a rigorous data preparation phase, harnessing the pandas library to organize and preprocess our data effectively. This included handling missing values and logically grouping tokens by document, setting a strong foundation for the modeling process.
To tackle the challenge of large text volumes, we employed the SlidingWindowDataset class. This technique allowed us to partition the text into segments of 512 tokens using a stride of 128, which was key to preserving the context throughout large documents. Such an approach was not only memory efficient but also essential for maintaining the accuracy of PII classification across extensive datasets.
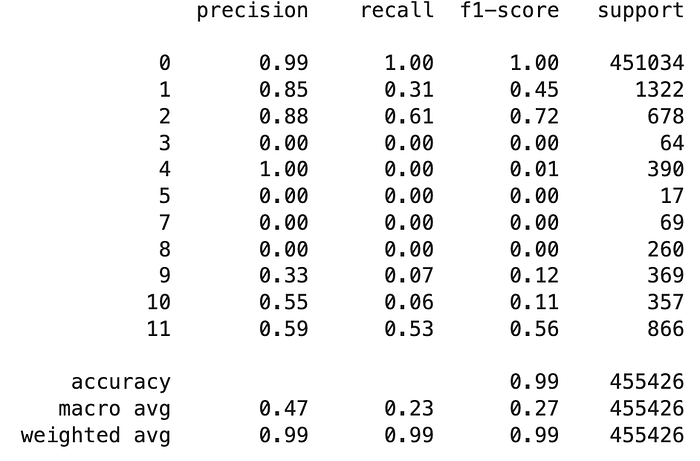
Performance Insights from the Classification Report
Delving into the classification report, the model’s performance varied across different classes:
- The most common class, denoted as ‘0’, achieved near-perfect precision and recall, indicating the model’s proficiency in correctly identifying non-PII tokens.
- The precision and recall for classes such as ‘1’ (0.85 precision, 0.31 recall) and ‘2’ (0.88 precision, 0.61 recall) show a considerable rate of accurate predictions but also suggest room for improvement in recall, particularly in retrieving all relevant instances of these PII types.
- Classes ‘3’, ‘5’, ‘7’, ‘8’ depict challenges in detection, with both precision and recall at zero, highlighting the difficulty the model faced with rare PII types, possibly due to insufficient training examples.
- Other classes like ‘9’, ‘10’, and ‘11’ demonstrated low recall, indicating that while the model could identify these PII types to some degree, it often missed them in the dataset.
Reflecting on the Model’s Effectiveness
The overall accuracy of the model stood at an impressive 99%, signifying its effectiveness in PII detection across the dataset. However, the macro and weighted averages suggest a disparity in the model’s ability to detect rarer PII types, which is an area identified for further development.
Mastering PII Detection with BERT: Architecture and Mechanism
Introduction to BERT
BERT, which stands for Bidirectional Encoder Representations from Transformers, is a groundbreaking language representation model developed by Google. It fundamentally changes the way machines understand human language by using a mechanism known as bidirectional training. This model is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, BERT is pre-trained on a large corpus of text and then fine-tuned for specific tasks, which allows it to achieve state-of-the-art results in a wide range of language processing tasks.
The Transformer in BERT
At the heart of BERT is the Transformer, a deep learning model that uses self-attention mechanisms to process words in relation to all other words in a sentence, contrary to previous models that processed words sequentially. This architecture, introduced by Vaswani et al. in “Attention is All You Need”, enables BERT to capture contextual relationships between words in a sentence from both directions, which is a significant enhancement over prior models that viewed sentences as a one-directional stream of words.
BERT’s Encoder Architecture
The BERT model uses what is known as the Transformer encoder architecture. Each encoder consists of two primary components:
- Self-Attention Mechanism: Allows BERT to consider the context of each word in the sentence to determine its meaning, rather than considering words in isolation.
- Feed-Forward Neural Networks: Each layer also contains a small feed-forward neural network that processes each word position separately. The output of these networks is what the next layer processes if there are subsequent layers.
Processes in BERT’s Encoder
- Tokenization: BERT begins processing its input by breaking down text into tokens.
- Input Embedding: Each token is then converted into numerical vectors that represent various linguistic features of the token.
- Positional Encoding: BERT adds positional encodings to the input embeddings to express the position of each word within the sentence.
- Self-Attention: The self-attention layers in the encoders allow each token to interact with all other tokens in the input layer, focusing more on the relevant tokens.
- Layer Stacking: Multiple layers of the Transformer encoder allow BERT to learn rich, context-dependent representations of the input text.
- Output: The final output is a series of vectors, one for each input token, which are then used for specific NLP tasks.
The BERT model’s ability to process words in relation to all other words in a sentence provides a deeper sense of language context and nuance, making it exceptionally effective for tasks requiring a deep understanding of language structure and context, such as PII detection.
BERT’s Implementation in PII Detection: Methodology, Results, and Impact
Finetuning a Bert Model
At the heart of our efforts was the BertForTokenClassification model, fine-tuned to navigate our dataset’s imbalances. To better detect less frequent PII types, we incorporated a weighted loss function, giving due importance to rarer labels.
- Sliding Window Tokenization: As shown in the code chunk below, his technique addressed the challenges of lengthy texts, preserving the entirety of information for the model to consider.
from transformers import BertTokenizerFast
import torch
# Initialize the tokenizer
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
def sliding_window_tokenization_and_labels(words, labels, max_len=512, slide_len=256):
tokenized_inputs = {
"input_ids": [],
"attention_mask": [],
"labels": []
}
# Process each sequence with sliding windows
start_index = 0
while start_index < len(words):
end_index = start_index + slide_len
window_words = words[start_index:end_index]
window_labels = labels[start_index:end_index]
# Tokenization and padding to max length
inputs = tokenizer(
window_words,
is_split_into_words=True,
add_special_tokens=False, # We already have [CLS] and [SEP] in our sequence
max_length=max_len,
padding='max_length',
truncation=True,
return_tensors='pt'
)
# Align labels with the tokenized word IDs, adding -101 for ignored tokens
word_ids = inputs.word_ids(0) # Batch index 0 since we're processing one sequence at a time
window_aligned_labels = [-101 if word_id is None else window_labels[word_id] for word_id in word_ids]
# Append the tokenized results
tokenized_inputs['input_ids'].append(inputs['input_ids'].squeeze(0))
tokenized_inputs['attention_mask'].append(inputs['attention_mask'].squeeze(0))
tokenized_inputs['labels'].append(torch.tensor(window_aligned_labels, dtype=torch.long))
# Move start index to the next slide
start_index += slide_len
# Stack all the tensors
tokenized_inputs['input_ids'] = torch.stack(tokenized_inputs['input_ids'])
tokenized_inputs['attention_mask'] = torch.stack(tokenized_inputs['attention_mask'])
tokenized_inputs['labels'] = torch.stack(tokenized_inputs['labels'])
return tokenized_inputs
- Handle Class Imbalance
import torch
import torch.nn as nn
# Calculate weights as the inverse of the frequency
weights = 1.0 / torch.tensor(list(label_freqs.values()), dtype=torch.float)
# Normalize the weights so that the most common class ('O') gets a weight of 1
weights = weights / weights[0]
# Move the weights to the device
weights = weights.to(device)
# Your loss function now uses these custom weights
loss_fn = nn.CrossEntropyLoss(weight=weights, ignore_index=-101)
To address class imbalance in classification tasks, we calculate weights inversely proportional to the frequency of each class in the dataset. These weights are then normalized to ensure that the most common class is assigned a weight of one, maintaining a reference scale. Finally, we define a CrossEntropyLoss function with these custom weights and specify -101 for the ignore_index parameter, allowing the model to ignore certain tokens (such as padding in sequence models) during loss computation. This approach helps mitigate the impact of class imbalance by prioritizing the learning of less frequent classes.
- Customized Training and Validation Cycles:
import torch
from transformers import BertForTokenClassification, AdamW, get_linear_schedule_with_warmup
import numpy as np
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
import torch.nn as nn
from sklearn.metrics import classification_report
import random
# Function to calculate accuracy per batch
def batch_accuracy(logits, labels):
# Get the predictions and compare with true labels
preds = torch.argmax(logits, dim=-1)
mask = labels != -101 # Exclude the -101 labels from calculation
corrects = (preds == labels) & mask # Correct predictions
accuracy = corrects.sum().item() / mask.sum().item()
return accuracy
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
# Learning Rate Adjustment Check
def get_current_learning_rate(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
# Begin training loop
best_val_loss = float('inf')
best_accuracy = 0
no_improve_epochs = 0
initial_model_params = [p.clone() for p in model.parameters()]
# Training loop
for epoch in range(num_epochs):
print(f"Current Learning Rate: {get_current_learning_rate(optimizer)}")
total_loss = 0
total_accuracy = 0
model.train()
for batch in train_dataloader:
input_ids, attention_masks, labels = batch
input_ids = input_ids.to(device)
attention_masks = attention_masks.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_masks)
loss = loss_fn(outputs.logits.view(-1, num_labels), labels.view(-1))
loss.backward()
optimizer.step()
scheduler.step()
total_loss += loss.item()
# Calculate batch accuracy from the logits and labels
batch_acc = batch_accuracy(outputs.logits, labels)
total_accuracy += batch_acc
avg_train_loss = total_loss / len(train_dataloader)
avg_train_accuracy = total_accuracy / len(train_dataloader)
print(f'Epoch {epoch + 1}, Train Loss: {avg_train_loss}, Train Accuracy: {avg_train_accuracy}')
model.eval()
val_loss = 0
val_accuracy = 0
with torch.no_grad():
for batch in val_dataloader:
input_ids, attention_masks, labels = batch
input_ids = input_ids.to(device)
attention_masks = attention_masks.to(device)
labels = labels.to(device)
outputs = model(input_ids, attention_mask=attention_masks)
loss = loss_fn(outputs.logits.view(-1, num_labels), labels.view(-1))
val_loss += loss.item()
# Calculate batch accuracy from the logits and labels
batch_acc = batch_accuracy(outputs.logits, labels)
val_accuracy += batch_acc
avg_val_loss = val_loss / len(val_dataloader)
avg_val_accuracy = val_accuracy / len(val_dataloader)
print(f'Epoch {epoch + 1}, Validation Loss: {avg_val_loss}, Validation Accuracy: {avg_val_accuracy}')
# Check if current epoch's validation loss is the best we've seen so far.
if avg_val_loss < best_val_loss:
torch.save(model.state_dict(), '/content/drive/My Drive/ML-Project/PII-DATA/best_model_state.bin')
best_val_loss = avg_val_loss
best_accuracy = avg_val_accuracy
no_improve_epochs = 0
else:
no_improve_epochs += 1
if no_improve_epochs >= patience:
print(f"Early stopping triggered at epoch {epoch + 1}.")
print(f"Best Val Loss: {best_val_loss}, Best Val Accuracy: {best_accuracy}")
break
The above code chunk aims at token classification tasks, using PyTorch and the Hugging Face Transformers library. The process begins by setting a seed for reproducibility across different runs, ensuring consistent initialization and behavior in stochastic operations.
- Imports and Setup: Necessary libraries are imported, including PyTorch for tensor operations and deep learning, Hugging Face’s Transformers for accessing pre-trained models and utilities, and Scikit-learn for evaluation metrics. Dataloader classes from PyTorch are used to handle data batching and shuffling.
- Batch Accuracy Calculation: A helper function
batch_accuracycalculates the accuracy of predictions in each batch. It filters out certain tokens (with a label of-101, typically used for padding or non-evaluated tokens) before comparing the predicted labels with true labels to compute accuracy. - Seed Initialization: The randomness is controlled by setting seeds for libraries like NumPy and PyTorch, ensuring that the results are reproducible.
- Learning Rate Retrieval: A function
get_current_learning_rateis defined to fetch the current learning rate from the optimizer, useful for monitoring and adjustments during training. - Training Loop Setup: The training loop is initialized with conditions to track the best validation loss and to implement early stopping if there’s no improvement in validation loss for a defined number of epochs (
patience). - Training and Validation Phases: During each epoch, the model undergoes training and validation phases. In the training phase, the model parameters are updated using the gradient descent method based on the loss computed from the model’s output and the actual labels. The validation phase evaluates the model on a separate dataset to monitor performance and avoid overfitting.
- Loss and Accuracy Tracking: For both training and validation, loss and accuracy are calculated. This information is used to determine model performance and make adjustments if necessary.
- Model Saving and Early Stopping: The best-performing model parameters are saved, and training can be halted early if there’s no improvement in validation loss over several epochs, preventing unnecessary computations and potential overfitting.
Understanding the Classification Report
The classification report provides a quantitative insight into the model’s performance:
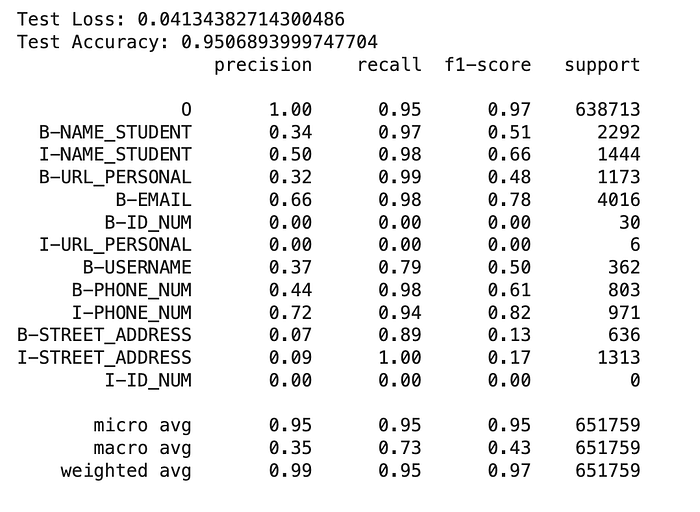
- Test Loss and Accuracy: The test loss stood at 0.0413, indicating the model’s prediction error, while the test accuracy reached an impressive 95.07%, reflecting the model’s ability to correctly classify the tokens as PII or non-PII.
Performance by Category:
- High Precision Classes: Classes like ‘B-EMAIL’ and ‘I-PHONE_NUM’ showed high precision, indicating that when the model predicted these classes, it was correct most of the time.
- High Recall Classes: The ‘B-NAME_STUDENT’ and ‘I-STREET_ADDRESS’ had high recall, meaning the model was able to identify most instances of these classes within the data.
- Challenges with Rare PII Types: Categories like ‘B-ID_NUM’ and ‘I-URL_PERSONAL’ had precision and recall scores of 0, suggesting the model struggled to identify these rare instances. This could be due to the small number of examples in the training data.
F1-Score and Support:
- The F1-score, a harmonic mean of precision and recall, was notably high for general classes but lower for rare types, indicating uneven model performance across different PII categories.
- The ‘support’ column, indicating the number of true instances for each label, helps to explain the disparity in F1-scores — categories with low support struggled with lower F1-scores.
Results and Impact
By integrating BERT into our PII detection initiative, we significantly improved our capability to identify and protect sensitive information within educational texts. The model’s high accuracy and efficient processing of voluminous texts demonstrate the transformative potential of advanced NLP technologies in safeguarding privacy in the digital educational landscape.
Conclusion and Future Directions for PII Detection in Education
Reflecting on Our Journey
Our exploration into the realm of PII detection in educational datasets has been both challenging and enlightening. By applying sophisticated NLP models like BERT and ELECTRA, we’ve made significant strides in protecting student privacy. Our methodology, from advanced tokenization to the nuanced application of BERT’s fine-tuned capabilities, has allowed us to detect a wide range of PII with high accuracy and efficiency.
Achievements and Learnings
We have seen that while BERT excels in recognizing and classifying common PII types, it encounters hurdles with rarer PII categories. The classification report illuminated these disparities, guiding our steps towards model improvement. Our commitment to ensuring comprehensive protection of sensitive information while maintaining the utility of educational datasets for research has been at the forefront of our efforts.
Charting the Path Forward
The field of PII detection is ever-evolving, and our work here is just the beginning. Future directions include:
- Enhanced Sampling and Representation: We plan to augment our dataset with more examples of rare PII to balance the representation across categories.
- Algorithmic Refinement: We aim to adjust model weights and explore alternative algorithms that might offer better performance, particularly in the context of rare PII detection.
- Continuous Learning and Adaptation: Keeping pace with the evolving nature of language and data privacy concerns, we’ll ensure our models continue learning from new data, enhancing their accuracy and reliability.
As we continue to refine our PII detection models, our commitment to safeguarding student privacy remains unwavering. The journey ahead is promising, and we are dedicated to advancing these tools to ensure educational data serves its purpose ethically and responsibly.
Authored by Emmanuel Agbeko Enyo , Sai Kiran Reddy Vellanki, Nishanth Nandakumar, Nandhini Devaraj and Harshita Madhukar Bharadwaj
 Certification")
")

{kind=link}