
Autism Spectrum Disorder (ASD) can be described as a condition which has behavioral and cognitive manifestations and is neurodevelopmental in nature. Its diagnosis is often complicated owing to the variability in symptom expression across individuals. In this research, we investigate the use of structural and functional Magnetic Resonance Imaging (MRI/fMRI) for identifying neuroanatomical features, which may be associated with ASD. Our aim is to improve diagnostic precision using machine-learned models, increasing understanding of the disorder’s underlying neurophysiology.
1. Introduction
Autism Spectrum Disorder (ASD) is a complicated condition concerning the brain, affecting how someone might talk, interact, and behave with other people. It’s called a “spectrum” because the degree of symptoms and disability varies greatly from one person to another. The more typical symptoms of ASD include problems with social interactions, speech and nonverbal communication difficulties, restricted behaviors, and limited range of interests or activities. It usually starts during early childhood, preceding the age of three, and is life-long. Despite there being no precise explanation for the causes of ASD, it is thought that a variety of genetic and environmental components that influence brain development are responsible.
ASD is one type of disability that shows a rapid increase across the globe. As a note, the Centers for Disease Control and Prevention CDC reported that in the year 2023, roughly 1 in 36 students in America were diagnosed with ASD. This rate seems to have gone up considerably compared to previous years, indicating the need for more efficient understanding and detection methods. The diagnosis of ASD, as with other non-verbal mental disorders, is particularly critical to implement at early stages. This is so that children with ASD are provided with appropriate therapies, assistance, and skill training which could help them improve profoundly in communication, functioning, and the overall quality of life. Nonetheless, current diagnostic systems are still largely dependent on observable behaviors alongside questioning.
Modern neuroimaging techniques allow scientists and medical professionals to study the brain’s anatomy and physiology in depth using MRI, fMRI or DTI scans. Neuroimaging has proven useful for examining patients suffering from various disorders like ASD. Furthermore, neuroimaging presents an objective alternative to behavioral assessments, allowing for an unbiased evaluation of patients suffering from Autism Spectrum Disorder.
There is a growing consensus regarding the role of MRI techniques in the research of autism and other neurodevelopmental disorders. MRI devices are readily available in hospitals, don’t require any intrusive procedures and can provide high accuracy imaging. MRI has been used for evaluating the brain volume of various regions and also assessing the cortex thickness, the shape of the brain, as well as the contour. It has been demonstrated that children suffering from autism spectrum disorders tend to have structural changes in certain regions of the brain that are associated with language or communication, social interaction and also sensory integration. The literature results lead to the consideration that MRI can be used, particularly with developed analytical algorithms, for the purpose of identifying changes associated with autism in the brain.
The main goal of this research is to analyze and detect Autism Spectrum Disorder using MRI data through a neuroimaging-based approach. This study aims to apply data processing techniques and machine learning models to identify patterns and features in brain scans that are associated with ASD. By doing this, the research hopes to contribute to the development of more accurate, faster, and objective methods for diagnosing ASD. Such advancements could improve early detection and provide better support for individuals affected by this disorder.
2. Literature Review
2.1 Current Diagnostic Methods for ASD (Clinical and Behavioral Assessments)
Autism Spectrum Disorder (ASD) is typically diagnosed through clinical and behavioral assessments. Doctors and psychologists observe a child’s behavior, communication, and social interactions to determine if they meet the criteria for ASD. The most commonly used tools include the Autism Diagnostic Observation Schedule (ADOS) and the Autism Diagnostic Interview-Revised (ADI-R) [1]. These tools rely heavily on trained professionals who assess the presence and severity of autism-related symptoms.
Although these methods are considered the gold standard, they come with some challenges. First, they are time-consuming and expensive, often requiring multiple sessions. Second, diagnosis can be subjective, as it depends on the judgment of the professional. In some cases, especially in under-resourced areas, there might be delays in diagnosis due to a shortage of specialists. These delays can prevent children from receiving early interventions, which are proven to be more effective when started at a young age [2].
2.2 Neuroanatomical Findings Related to ASD
Many studies have tried to understand how the brain of a person with autism is different from that of a typical person. Research has shown that people with ASD often have structural differences in certain brain regions. For example, abnormalities have been observed in the amygdala (which controls emotions), the hippocampus (involved in memory), and the prefrontal cortex (responsible for decision-making and social behavior) [3].
Some studies also suggest that children with ASD may have larger total brain volumes in early childhood, a condition known as early brain overgrowth [4]. This unusual brain development pattern can affect how different parts of the brain communicate with each other. The corpus callosum, which connects the two brain hemispheres, has also been reported to be thinner in individuals with ASD, indicating disrupted connectivity between brain regions [5].
2.3 Use of MRI in ASD Research: Structural vs. Functional MRI
MRI is a powerful tool used in ASD research to study both the structure and function of the brain. Structural MRI (sMRI) gives detailed images of brain anatomy and is used to measure the size, shape, and thickness of different brain areas. This helps researchers identify physical changes or abnormalities in the brains of individuals with autism [3].
On the other hand, functional MRI (fMRI) measures brain activity by detecting changes in blood flow. It helps to study how different parts of the brain communicate and work together during tasks or at rest. In people with ASD, fMRI has shown reduced connectivity between brain regions involved in social interaction, language, and sensory processing [6]. This method has been very useful in identifying differences in brain function that are not visible through structural MRI alone.
2.4 Machine Learning and Deep Learning Techniques in ASD Detection
With the rise of artificial intelligence, researchers are now using machine learning (ML) and deep learning (DL) to detect ASD from MRI data. Machine learning algorithms like Support Vector Machines (SVM), Random Forests, and Logistic Regression can classify brain images into ASD or control groups based on specific features such as volume or cortical thickness [7]. These models are trained using labeled datasets and can learn patterns that distinguish ASD brains from non-ASD brains.
Deep learning models, especially Convolutional Neural Networks (CNNs), have shown even better performance because they can automatically extract complex features from raw MRI images. For example, 3D CNNs can analyze the whole brain as a three-dimensional image, capturing subtle differences in structure or function [8]. These approaches have the potential to improve diagnostic accuracy and reduce reliance on subjective assessments.
2.5 Summary of Key Studies and Their Findings
Several important studies have advanced the understanding of ASD through MRI analysis. For example:
Hazlett et al. (2017) showed that increased brain volume in infants at high risk for autism could predict a later diagnosis.
Ecker et al. (2010) used structural MRI to find differences in the shape and folding of the cerebral cortex in adults with ASD.
Di Martino et al. (2014) introduced the Autism Brain Imaging Data Exchange (ABIDE), a large open-access dataset that has enabled many MRI-based ASD studies using machine learning.
Khosla et al. (2019) used a deep learning model on fMRI data and achieved strong classification performance across multiple datasets.
These studies have shown that brain imaging, especially when paired with AI, has the potential to transform how we detect and understand ASD.
2.6 Limitations in Current Research
Despite the progress, there are still several gaps in the current research. First, many studies use small sample sizes, which limits the generalizability of the results [9]. Second, MRI data can vary depending on the machine, scanning protocol, and location, making it difficult to build models that work across different datasets.
Also, while machine learning models can perform well, they sometimes act like a “black box”, meaning it’s hard to understand exactly how they make their decisions. This lack of transparency can make it difficult for doctors to trust or use these models in clinical practice [10]. Furthermore, many existing studies focus on binary classification (ASD vs. control) without considering the full spectrum of autism, which includes a wide range of abilities and symptoms.
To address these challenges, future research should focus on collecting larger, multi-site datasets, improving model interpretability, and combining multiple data types (e.g., genetics, behavior, MRI) for a better understanding of ASD.
3. Methodology
3.1 Overview
In an era where artificial intelligence is revolutionizing healthcare diagnostics, this individual research project explores the potential of deep learning in detecting Autism Spectrum Disorder (ASD) from 3D brain MRI scans. The focus was on developing an end-to-end pipeline that integrates medical image processing, deep neural network modeling, and cloud-native infrastructure to create a scalable and efficient diagnostic tool. The goal was to leverage modern computational resources and methods to support early and objective detection of ASD using neuroimaging data.
3.2 MRI Dataset
The dataset used for this project was obtained from the Autism Brain Imaging Data Exchange (ABIDE), one of the most used public repositories for autism research. ABIDE provides openly accessible brain imaging data from individuals diagnosed with Autism Spectrum Disorder (ASD), as well as data from typically developing (TD) control subjects. This rich dataset is collected from multiple research sites around the world and includes standardized clinical, behavioral, and demographic information alongside the imaging data, making it highly valuable for neuroimaging-based autism studies. For this study, a total of 1,164 3D structural MRI scans were used. It included:
547 MRI scans of individuals diagnosed with ASD
617 MRI scans of control subjects (non-ASD)
The images were all in NIfTI (.nii) format, which is a standard file format widely used in neuroimaging. The type of scans used were T1-weighted structural MRIs, known for providing high-resolution images of the brain’s anatomy, including detailed views of gray and white matter structures. These images are especially useful for studying morphological differences in the brain, which are often explored in ASD research. Before these images were used for training the machine learning models, a series of preprocessing steps were applied to ensure consistency and compatibility across the entire dataset
All scans were in NIfTI (.nii) format and were high-resolution 3D structural T1-weighted MRI images. Before model training, the volumes were preprocessed to maintain consistency across samples thus all MRI volumes were:
Resized to a uniform shape of (80, 128, 128)
Normalized for voxel intensity values across the dataset
This resizing step was important because the original scans came in different dimensions due to differences in scanning equipment and protocols across research sites. Standardizing the shape of all volumes ensured that they could be fed into the model without dimensional conflicts.
Next, the MRI images were normalized for voxel intensity values. Normalization is a common preprocessing technique in medical imaging that adjusts the intensity values (i.e., the brightness or contrast levels) of each voxel in the brain image to fall within a consistent range. This step helps to reduce the impact of imaging artifacts, scanner variability, and individual differences in brain signal intensity. By bringing voxel values onto a similar scale, the deep learning model can more easily learn meaningful features without being misled by irrelevant intensity differences.
These preprocessing steps helped create a clean, uniform dataset suitable for machine learning-based classification. The prepared dataset provided a solid foundation for the next phase of the research, which involved designing, training, and testing deep learning models to detect ASD-related patterns in brain structure.
3.3 Data Augmentation and Splitting
# Albumentations pipeline
augment = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.3),
A.ShiftScaleRotate(shift_limit=0.05, scale_limit=0.05, rotate_limit=20, p=0.3),
])
# 80-20 train-test split
split_idx = int(0.8 * len(X_batch))
X_train, X_test = X_batch[:split_idx], X_batch[split_idx:]
y_train, y_test = y_batch[:split_idx], y_batch[split_idx:]
# Augment only training data
X_aug, y_aug = [], []
for x, y in zip(X_train, y_train):
for _ in range(AUGMENT_RATIO):
X_aug.append(augment(image=x)["image"])
y_aug.append(y)
To address the disparity in sample size for the ASD and control group as well as the limited dataset, augmentation techniques were used in the model training to minimize overfitting. Using the tf.image library in TensorFlow, augmentation operations were performed exclusively on the training set to prevent data leakage and ensure proper evaluation on the test data. A set of transformations such as image rotation, flipping, and scaling were performed to expand the representation of training images. These transformations helped mimic natural variations in MRI image acquisition, such as changes in brain orientation or size, while maintaining the structural integrity of the images. Augmentation provided the model with a more diverse set of brain images which enhanced its generalization capabilities, enabling the model to learn more useful features. In addition, these techniques helped balance the representation of ASD cases and control cases in the training process.
Data Split:
80% training, 20% testing
Training Set (post-augmentation):
437 ASD scans → augmented to 1,748 samples
493 control scans → augmented to 1,972 samples
Test Set (unaugmented):
110 ASD scans
124 control scans
All datasets were saved in .npy format and stored on Google Cloud Storage for efficient access during training.
3.4 Model Architecture
The initial modeling approach involved developing a custom 3D Convolutional Neural Network (CNN) using TensorFlow, designed specifically to process the 3D MRI volumes and perform binary classification between ASD and control subjects. Despite careful tuning of the architecture and training parameters, the model struggled to learn meaningful features from the data and consistently plateaued at around 50% accuracy, which is equivalent to random guessing in a binary classification task. This indicated that the model was not effectively capturing the complex structural differences associated with ASD.
To overcome this limitation, the project adopted a transfer learning strategy using pretrained models from the MedicalNet library, which provides 3D CNN architectures trained on large-scale medical imaging datasets. In particular, variants of the 3D ResNet architecture such as ResNet-18 and ResNet-50 were selected and adapted for binary classification. These models, having already learned to extract relevant features from volumetric medical data, offered a more robust starting point than training a model from scratch, and were expected to perform better in identifying subtle patterns related to ASD in brain MRI scans:
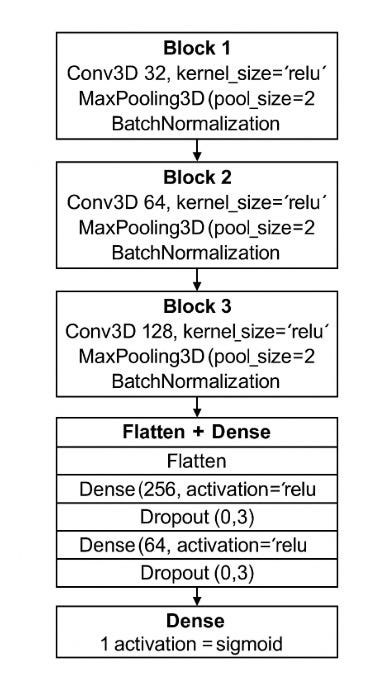
Input: 3D MRI volume (80, 128, 128)
Output: Binary prediction (ASD or control)
Pretrained weights: Derived from medical imaging datasets
These models were customized using a local resnet.py script, allowing flexibility in experimenting with different depths and configurations.
3.5 Training Infrastructure
Training was conducted on Google Cloud Platform (GCP) using a high-performance virtual machine setup:
GPU: NVIDIA L4
CPU: 32 virtual cores
Memory: 128 GB RAM
Storage: Cloud-based .npy datasets on GCP buckets
This infrastructure enabled efficient training and parallel processing of 3D data, significantly reducing overall computation time and avoiding local hardware limitations.
3.6 Testing and Evaluation
Model evaluation was performed on the unaugmented test set using the following classification metric:
Final Test Accuracy: 57%
Although the accuracy was modest, it highlights the complexity of classifying ASD using only structural MRI and suggests the need for more refined architectures and multimodal data.
3.7 Challenges Faced
This project encountered several significant challenges throughout the development and implementation process:
Model Convergence Issues:
The initial custom 3D CNNs struggled to learn meaningful patterns from the MRI scans. Despite applying standard techniques like data augmentation, normalization, and early stopping, the models consistently plateaued at around 50% accuracy, equivalent to random guessing in binary classification. This indicated that the network was not successfully capturing the structural differences between ASD and control groups.
Memory Limitations:
Processing high-resolution 3D MRI data requires large amounts of memory. During training, frequent OutOfMemory (OOM) errors occurred, especially when batch sizes were increased or when complex model architectures were used. This made it difficult to train models efficiently and required careful tuning of batch size, model depth, and input shape.
Transfer Learning Compatibility:
Integrating pretrained models introduced additional technical difficulties. Some models, such as MONAI’s DenseNet121, were originally designed for 2D medical images and did not support 3D input volumes. These models required extensive architectural modifications or had to be abandoned altogether in favor of more suitable 3D-compatible frameworks like MedicalNet.
Cloud Resource Quotas:
Initially, training was conducted on Microsoft Azure, but GPU access was limited due to platform-imposed quotas. These restrictions slowed progress and limited experimentation with deeper networks. To overcome this, the project migrated to Google Cloud Platform (GCP), which provided better flexibility, access to high-performance NVIDIA L4 GPUs, and improved scalability.
Evaluation and Integration Complexity:
The use of .npy files (NumPy arrays) to store preprocessed 3D volumes required custom batch loading and evaluation scripts, particularly when integrating with PyTorch-based MedicalNet models. Since these models were not originally designed to work with .npy input pipelines, custom code was needed to handle loading, batching, and testing, which added time and complexity to the evaluation phase.
4. Adult and Children Screening Data
This study presents a comprehensive machine learning pipeline designed to predict Autism Spectrum Disorder (ASD) in adults and children using structured data from two separate screening datasets. The process integrates data preprocessing, feature engineering, model training, evaluation, and explainability, with a focus on managing class imbalance and improving diagnostic interpretability.
4.1 Dataset Description and Preprocessing
The datasets used in this study were obtained from public ASD screening repositories in CSV format, comprising two distinct files: adult.csv and children.csv. Each file contains multiple features related to behavioral patterns, demographic characteristics, and prior clinical history relevant to ASD.


Initial preprocessing steps included the removal of redundant columns such as age_desc and the treatment of missing values, particularly in categorical variables like ethnicity, which were filled with the placeholder “Unknown.” Age values equal to or greater than 100 were considered outliers and excluded. To ensure consistency across the dataset, categorical variables (e.g., gender) were standardized to lowercase formats.
4.2 Feature Engineering
Binary categorical columns (e.g., “yes”/“no”) were converted to numerical format using binary encoding (1 for “yes,” 0 for “no”). The target variable, class, was similarly encoded (1 for “YES” indicating ASD, and 0 for “NO” indicating non-ASD). Dataset-specific columns such as family_pdd for adults and autism for children were handled independently to reflect their differing diagnostic criteria.
4.3 Data Splitting and Transformation
Both datasets were stratified based on the target variable and split into training (80%) and testing (20%) sets to preserve the distribution of ASD and non-ASD cases. Feature types were identified and separated into numerical (e.g., age) and categorical features (e.g., gender, ethnicity). Numerical features were scaled using MinMaxScaler, while categorical features were one-hot encoded using OneHotEncoder. To prevent target leakage, columns like result, which may contain post-screening outcome data were explicitly dropped prior to training.
4.4 Model Pipeline and Class Imbalance Handling
Three supervised learning algorithms were evaluated:
- Random Forest: Optimized using GridSearchCV for key hyperparameters including n_estimators and max_depth.

Random Forest — Adult Dataset
The confusion matrix shown represents the performance of a Random Forest classifier applied to the adult ASD dataset. In this matrix, the rows represent the actual classes (0 = non-ASD, 1 = ASD), and the columns represent the predicted classes. The model correctly predicted 101 non-ASD cases (true negatives) and 33 ASD cases (true positives). It misclassified 2 non-ASD individuals as having ASD (false positives) and 5 ASD individuals as non-ASD (false negatives). Overall, the classifier demonstrates strong predictive performance, particularly in identifying non-ASD individuals, while still achieving reasonable accuracy in detecting ASD cases. The relatively low number of false predictions indicates a well-balanced model.
- Logistic Regression: Employed L1-regularization and class_weight=’balanced’ to manage class imbalance.
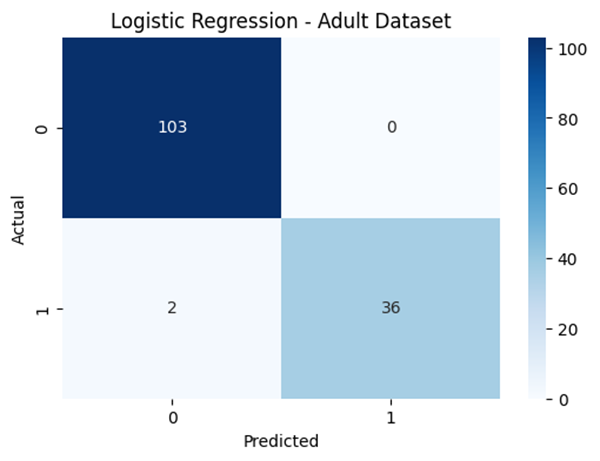
Logistic Regression — Adult Dataset
The confusion matrix displays the performance of a Logistic Regression model on the adult ASD dataset. It shows that the model perfectly classified all 103 non-ASD individuals (true negatives) with zero false positives, and correctly identified 36 out of 38 ASD cases (true positives). Only 2 ASD cases were misclassified as non-ASD (false negatives). This indicates high precision and recall, especially for the non-ASD class. The model demonstrates excellent overall performance, particularly in its ability to accurately distinguish between ASD and non-ASD individuals with minimal error.
- XGBoost: Applied an adjusted scale_pos_weight parameter to account for the imbalance between ASD and non-ASD classes.
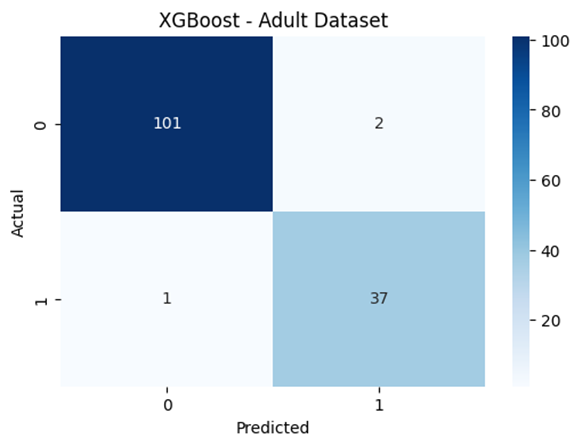
The confusion matrix illustrates the performance of the XGBoost classifier on the adult ASD dataset. The model accurately predicted 101 non-ASD individuals (true negatives) and 37 ASD individuals (true positives). It made only 2 false positive predictions, incorrectly labeling non-ASD cases as ASD, and just 1 false negative, where an ASD case was incorrectly classified as non-ASD. These results indicate that the XGBoost model achieved high overall accuracy, with excellent precision and recall for both classes, making it a strong performer for binary classification in this ASD prediction task.
To further address class imbalance in the training set, Synthetic Minority Oversampling Technique (SMOTE) was applied. Additionally, SelectFromModel using L1-penalized Logistic Regression was implemented to retain only the most informative features prior to model fitting.
4.5 Model Evaluation Metrics
Model performance was evaluated using a range of metrics well-suited for binary and imbalanced classification tasks:
- Accuracy
- Precision
- Recall
- F1-Score
- Specificity
- ROC-AUC (Receiver Operating Characteristic — Area Under Curve)
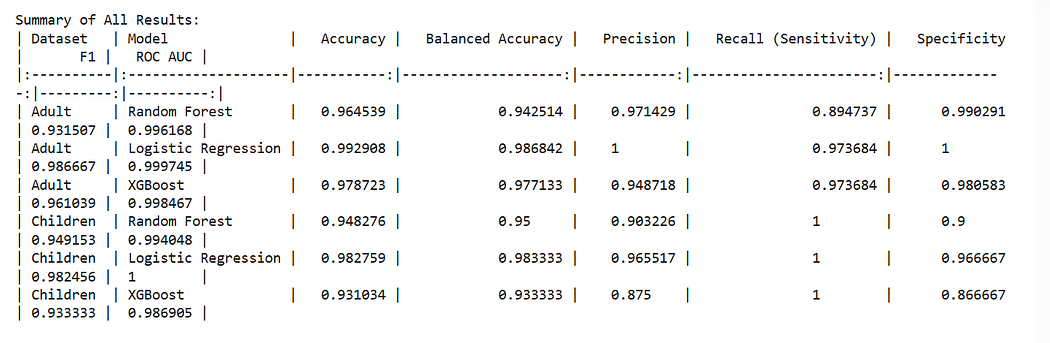
Evaluation also included visual tools such as confusion matrices, ROC curves, and precision-recall curves, allowing for a deeper understanding of model strengths and weaknesses.
4.6 Model Interpretability and Feature Importance
To promote transparency and interpretability, feature importance was extracted and visualized for all models. For tree-based models (Random Forest, XGBoost), feature importances were derived from information gain. For Logistic Regression, importance was based on the magnitude of model coefficients. Furthermore, SHAP (SHapley Additive Explanations) values were computed for tree-based models to explain individual predictions and assess the global influence of each feature.
4.7 Additional Exploratory Analysis
To support modeling efforts, exploratory data analysis (EDA) was conducted on both datasets. Class distributions were visualized to examine the balance between ASD and non-ASD cases. Age distributions across classes were explored using boxplots, revealing patterns such as a higher concentration of ASD cases in younger children, which may be indicative of early onset behavioral markers.


4.8 Output Generation and Model Persistence
The best-performing model for each dataset was serialized using .joblib and stored for future deployment or integration into real-time screening systems. Model performance metrics were compiled into Markdown tables to facilitate easy comparison across classifiers. The pipeline includes built-in error-handling routines (via try-except blocks) to manage failures, particularly during SHAP analysis, ensuring robust execution.
4.9 Strengths and Limitations
This pipeline emphasizes reproducibility by setting a consistent random seed (np.random.seed(42)) and designing modular, reusable functions (e.g., evaluate_model()). It also incorporates interpretability tools that are essential for clinical applications. However, there is room for further enhancement, including the exploration of interaction terms, the application of nested cross-validation for more rigorous hyperparameter tuning, and the integration of models into web-based tools or APIs for scalable deployment.
Summary and Conclusion
This research project explored the use of deep learning techniques to detect Autism Spectrum Disorder (ASD) using 3D brain MRI data from the publicly available ABIDE dataset. The dataset consisted of 547 ASD and 617 control .nii-formatted MRI scans, which were preprocessed by resizing to a uniform shape and normalizing voxel intensities. To address class imbalance and enhance generalization, TensorFlow-based data augmentation was applied at a 3:1 ratio on the training set, resulting in a significantly expanded dataset for model training.
The initial implementation using a custom-built 3D Convolutional Neural Network (CNN) failed to exceed 50% accuracy, prompting a shift toward transfer learning. A pretrained 3D ResNet architecture from the MedicalNet model library was adapted for binary classification of ASD vs. control subjects. The model was trained on Google Cloud Platform using high-performance infrastructure (NVIDIA L4 GPU, 32 vCPUs, and 128 GB RAM), which enabled efficient batch processing of large 3D volumes.
Despite several technical challenges such as memory management issues, model convergence difficulties, incompatibility with some pretrained networks, and cloud resource limitations, the final model achieved a test accuracy of 57%. While modest, this performance reflects the inherent complexity of detecting ASD from brain structure alone and emphasizes the need for more advanced and domain-specific architectures.
Ultimately, this project demonstrates the potential of combining AI, medical imaging, and cloud computing to support early, objective detection of ASD. Future work will focus on refining model architecture, integrating volumetric transformers, and incorporating clinical metadata to enable multi-modal learning aiming for more accurate and explainable diagnostic systems that can contribute to real-world clinical practice.
The detailed code is available in GitHub: https://github.com/Aparna003/Autism_detection
References
[1] Lord, C., Rutter, M., DiLavore, P. C., & Risi, S. (2000). Autism Diagnostic Observation Schedule (ADOS). Journal of Autism and Developmental Disorders, 30(3), 205–223.
[2] American Psychiatric Association. (2013). Diagnostic and Statistical Manual of Mental Disorders (5th ed.). Washington, DC: Author.
[3] Ecker, C., Marquand, A., Mourão-Miranda, J., et al. (2010). Describing the brain in autism in five dimensions — MRI-assisted diagnosis using a multi-parameter classification approach. Journal of Neuroscience, 30(32), 10612–10623.
[4] Hazlett, H. C., Gu, H., Munsell, B. C., et al. (2017). Early brain development in infants at high risk for autism spectrum disorder. Nature, 542(7641), 348–351.
[5] Just, M. A., Cherkassky, V. L., Keller, T. A., et al. (2007). Functional and anatomical cortical underconnectivity in autism: Evidence from an fMRI study and corpus callosum morphometry. Cerebral Cortex, 17(4), 951–961.
[6] Nielsen, J. A., Zielinski, B. A., Fletcher, P. T., et al. (2014). Multisite functional connectivity MRI classification of autism: ABIDE results. Frontiers in Human Neuroscience, 8, 205.
[7] Arbabshirani, M. R., Plis, S., Sui, J., & Calhoun, V. D. (2017). Single subject prediction of brain disorders in neuroimaging: Promises and pitfalls. NeuroImage, 145, 137–165.
[8] Heinsfeld, A. S., Franco, A. R., Craddock, R. C., et al. (2018). Identification of autism spectrum disorder using deep learning and the ABIDE dataset. NeuroImage: Clinical, 17, 16–23.
[9] Abraham, A., Milham, M. P., Di Martino, A., et al. (2017). Deriving reproducible biomarkers from multi-site resting-state data: An Autism-based example. NeuroImage, 147, 736–745.
[10] Plitt, M., Barnes, K. A., & Martin, A. (2015). Functional connectivity classification of autism identifies highly predictive brain features but falls short of biomarker standards. NeuroImage: Clinical, 7, 359–366.



{kind=link}